A revamped Interface Code Generator and associated type aware memory management library developed for the Trick Simulation Environment.
Overview
This project consists of 2 parts - the Interface Code Generator and the runtime memory management library. The general idea is that we can add reflection to C++ by generating type information, and then use that information at runtime along with a memory management library to enable checkpoint and restore of arbitrary data structures, variable lookup by name, and more.
Interface Code Generator
The Interface Code Generator reads header files and generates data type information about the class definitions in them. This data type information is in the form of DataType object instantiations in header files named io_<header_name>.hpp
ICG uses Clang's AST generation feature to understand the header files it is given. It implements a recursive AST traversal algorithm, similar to what is implemented by Clang's more sophisticated LibTooling and ASTMatchers. ICG only cares about class/struct definitions, class template definitions, and typedefs. It gathers this information into an intermediate representation, and then uses that to create a header file io_<header_name>.hpp that instantiates DataType objects based on the information that was gathered from the AST. This file is generated using a custom built template engine, contained in ICGTemplateEngine/.
DataTypes
The DataType is the representation we use to understand type structure at runtime. DataType is the base class of a hierarchy of types that can be used to represent all supported types. The derived classes include:
The DataType interface provides some basic operations over types that can be used to implement more complex algorithms. Includes getTypeName(), getSize(), the ability to allocate and delete an instance, and the ability to get and set the value given an address (using the Value class hierarchy).
DataTypes also support a Visitor pattern with double dispatch. Every DataType has an accept (DataTypeVisitor *) -> bool method which should be used to call the correct method in the DataTypeVisitor class. These visitors are used to implement checkpoint and lookup algorithms.
The entity responsible for managing the types is the DataTypeInator. The DataTypeInator holds a TypeDictionary, which tracks all BaseTypes. The DataTypeInator's most important method is resolve(string) -> DataType *. This will either apply a modifier type or lookup a base type in the type dictionary, and return the appropriate type.
This requires runtime memory management. All allocations must be allocated through or registered with the MemoryManager. The memory manager tracks allocations using a class called AllocInfo, which contains address, name, size, and DataType* of a particular allocation.
Supported Types
Currently, supported C++ features are:
- Primitives: voidcharshortintlongwchar_tlongunsignedunsigned charunsigned shortunsigned intunsigned longfloatdouble
- std::string
- Constrained Arrays
- Pointers
- Classes and structs
- Namespaces
- Nested classes
typedefandusingstatements- Inheritance
- Class templates
- STL sequences (vector, list, deque)
- Any mix of the above
Clone
Use a recursive clone to include the repository's submodules
Build
Use the normal CMake process to build.
Tests are built along with the normal build process (should probably separate that out later).
Run tests through ctest (or make test)
Usage
See the test/ directory for examples of intended usage.
Documentation
How it all fits together
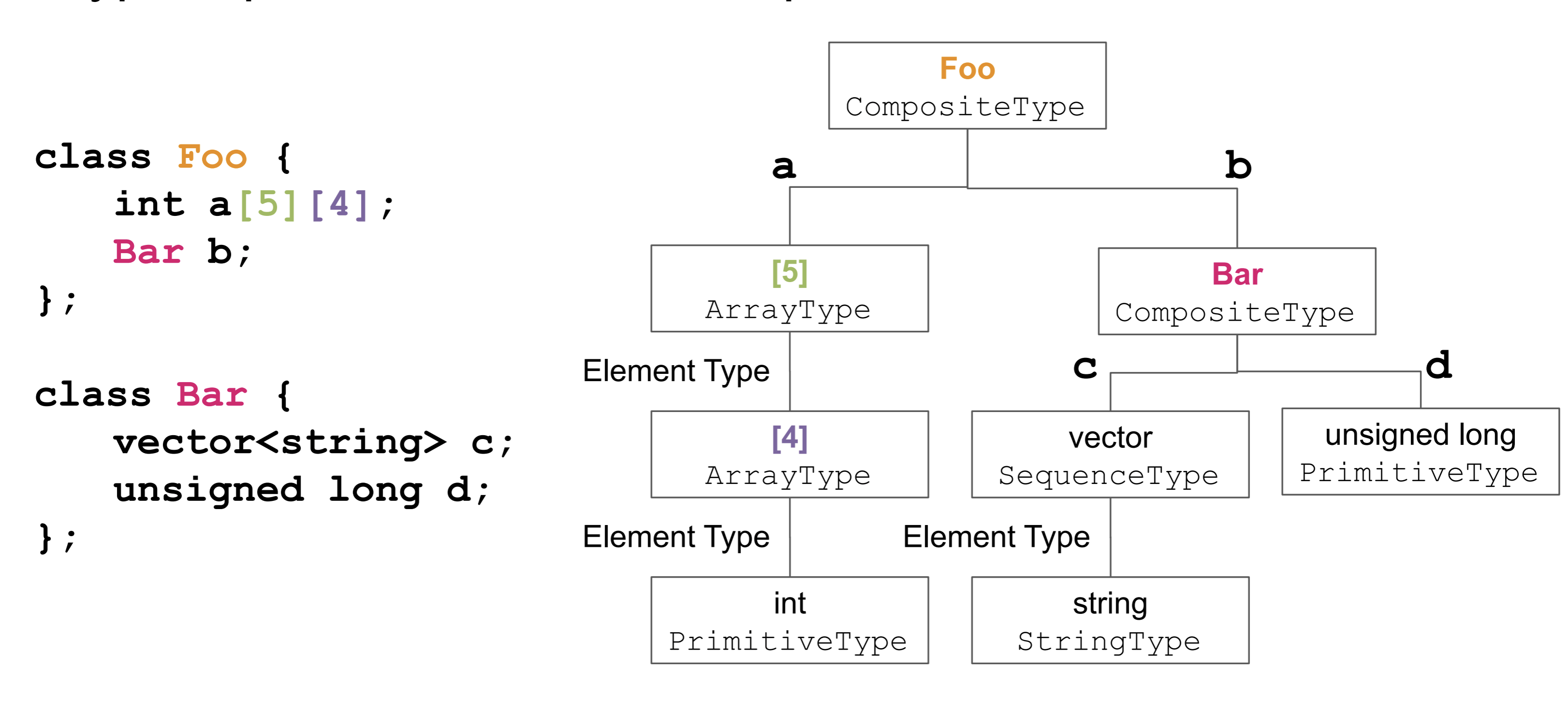
Here's the full "composite tree" structure of a DataType would look like:
Here's a view of what the memory manager would hold:

Here's how you put that information together to implement assignment from string:

AST Generation
To generate the Abstract Syntax Tree, use Clang's built in -ast-dump utility. An AST can be dumped manually as follows:
This will dump out the entirety of the AST, including the system headers. Clang also provides the ability to dump parts of the AST filtered on a keyword:
To dump an AST with the system headers filtered out, use this utility. TODO: pull this here as another executable, for debugging convenience.
This works by pulling the system paths from the command:
And then pruning the AST of branches that live in these file paths.
AST Traversal
All of the information that ICG needs is contained in the AST, hopefully. Currently, everything can be scraped with a simple traversal model.
The traversal code lives in Traversal.cpp. These functions work by passing json nodes around, and returning an ASTInfo object that contains all of the information scraped from within the node. Each node type of interest (top level AST, class, field, class template declaration, class template specialization, typedef statement) has an associated scrape_<nodetype>_info function that should be called when a node of that kind is found.
Notes about LibClang
This project was started with LibClang, but I switched to parsing the JSON AST myself. This is because that I came across serious limitations and bugs with LibClang that made it near unusable. For example, LibClang does not expose the branches of the AST with class template specializations. LibClang sometimes just mysteriously breaks as well. I decided to parse the bare AST myself because it contains all the necessary information.
Template Engine
The code that is outputted by ICG is generated using a template engine (similar in concept to mustache).
The template engine works by taking "templates", which are strings with "blanks" for tokens to be inserted, and recursively populating them with other templates or provided data. The templates used by ICG live in ICG_io_src_templates.hpp.
All blanks are denoted as {{tokenname}}. There are two types of blanks - normal and list. If the token's name is formmated like list_{listname}_{tokenname}, it is a list token.
Normal token example:
The steps to populate this token are as follows:
- Look up a token with the name "filename" from the token dictionary. It will be something like "foo.hpp"
- Recurse into this token with the same dictionary. In this case, the file name will not contain other blanks to be filled, so this will just return "foo.hpp"
- Use string replacement to replace
{{filename}}withfoo.hpp
List token example:
Steps to populate this token:
- Parse the token name - since it starts with
list_, interpret as a list token. The list name isclassesand the token name isclass_type_decl. - Look up the token,
class_type_decl, from the token dictionary. - Find the new tokens to add to the dictionary by looking up the
classeslist from therecursable_lists_dictionary.- If the list does not exist, do not recurse and replace this token with an empty string.
- Iterate through the list items. For each item in the list:
- Add this item's dictionary to the overall dictionary
- Recurse into the template string for
class_type_decland populate it fully. - Concatenate this result on to the overall token result.
- Use string replacement to replace
{{list_classes_class_type_decl}}with the overall token result.
The structure that enables this recursive list population is an interface called recursable. ClassInfo, FieldInfo, TypedefInfo, and StlDeclInfo all implement recursable.
Get the token name -> token value map for this object. For a class info, this returns -
To recurse into an object, use this function:
This returns nested lists that live under this object. Often it returns empty. For a class info, it returns -
Overall, a class info might look something like this, if it was structured like a json:
Note: I coded this before I committed to having json as a dependency. Maybe we should get rid of the recursable thing and just use json objects.
DataTypeInator
The DataTypeInator is the central manager for DataTypes. DataTypes and TypeDef statements are registered with the DataTypeInator at initialization time (by ICG generated code). The main purpose of the DataTypeInator is to provide the transformation between string representation of a type to DataType*.
This function can only look up an existing type, not create a new one. The only exception is arrays and pointers - this function may create a new ArrayDataType or an new PointerDataType, with a subtype an existing type or another array/pointer type.
This resolve function handles arrays/pointers, typdefs, and qualifiers.
The DataTypeInator has 2 structures under the hood - a TypeDictionary and a TypeDefDictionary. The TypeDictionary is a map from string->DataType* that contains all of the data type tranformations, and the TypeDefDictionary is map from string->string that contains all alias->canonical name tranformations. The values in the TypeDefDictionary are always canonical names.
Memory Manager
The MemoryManager here is meant to conform to the interface of the current Trick memory manager as closely as possible.
The interface for declaring a variable is as follows:
If an allocation is provided, then it is registered and considered an extern alloc. If one is not provided, then the memory manager will allocate memory of the correct type, using the DataType's allocator, and return the new address, this is considered a local alloc.
Examples:
When delete_var is called, a local allocation will be deallocated using the DataType's deallocator, and an extern allocation will simply be unregistered. The memory manager's destructor will deallocate all local allocations.
Each AllocInfo contains the name, DataType, starting address, and size of the allocation. This means that given an address, the memory manager can locate the allocation that contains it, and then use its DataType to figure out the exact name of the variable at that location.
DataType
The DataType is the base class of a hierarchy of types that can be composed to represent all types. Each data type has a size, string representation, and an allocator and deallocator for the type. Subclasses hold information and operations specific to their own structure.
- Types that represent a literal (string, primitive) have the ability to get or set a value given an address.
- CompositeDataType has a map of its member's members, including member name, DataType*, and offset of each.
- ArrayDataType has the number and DataType* of it's elements, from which it can calculate the offset of each.
Some DataType subtypes need to take the type they are representing as a template parameter
- SpecifiedPrimitiveDataType <T>
- SpecifiedCompositeDataType <T>
- SpecifiedSequenceDataType <T>
C++ does not allow for a virtual templated function, which is necessary for implementing visitor algorithms, so these must inherit from a non-templated class that introduces the specialized interface.
Algorithms over DataTypes
In order to write effective algorithms over DataTypes, you must have access to the subclass's interface. This is accomplished by implementing a visitor pattern with double dispatch.
The DataType interface has this method to accept a visitor:
The DataTypeVisitor interface has specialized functions for each visitiable DataType subclass:
Each visitable DataType implements the accept method by passing its this pointer into the appropriate visitor method, such as:
Using this method, a Visitor class can traverse the DataType tree without having to use dynamic_cast.
All algorithms in the Algorithm/ folder work by implementing a visitor class. Since a visitor class cannot change the arguments or return value of the visit methods, it must keep intermediate state as member variables in itself. The visitor classes are meant to be "one-shot", and the intended entry points are in the DataTypeAlgorithm namespace.
Visitor algorithms can traverse an entire tree (FindLeaves, PrintValue), search the tree (LookupNameByAddressAndType, LookupAddressAndTypeByName), or execute one specific operation with target type(s) on a DataType* value (GetValue, AssignValue, ResizeSequence).
This is really important - the key concept that makes the DataType concept work is that there is NEVER any special case code for a subType within a datatype, or really within any of the bigger management structures. ALL of this special case code should only ever exist in the Visitor algorithms. Within the visitor methods, the same concept applies - the visitCompositeType method should NEVER have special case code that depends on the type of a member, it should always just recurse into it or pass to another visitor algorithm.
Checkpointing
The checkpoint strategy is overall the same as current Trick, but the implementation is very different.
The CheckpointAgent interface is replaced with a simplified interface, so checkpoint agents that use different formats could easily be written.
The default checkpoint agent here is called J_CheckpointAgent (for Jackie checkpoint agent i guess) which writes checkpoints in the same format as the current default Trick checkpoint agent, with some small addditions.
Local variable declarations come first, then all assignements.
The difference is the addition of commands. There are 2 commands implemented -
These are pretty loose, and could easily be changed. The RESIZE_STL command MUST be present and before any assignments in the STL to ensure that the stl that is being restored has the correct capacity.
Checkpointing with Pointers
This library handles checkpointing pointers the same way that Trick currently does. However, the visitor algorithms LookupAddressAndTypeByName and LookupNameByAddressAndType make it really easy to do this compared to the current Trick implementation.
Composite Types
Composite types are defined by template specialization. This done to implement inheritance.
Consider the class structure:
The CompositeDataType for the grandparent class, A, would look like:
The getMemberMap() function simply returns a statically defined map containing all the member information. This is used at runtime.
The applyMembersToDerived() function is only used at initialization time. This function takes a template parameter, <Derived>, which is used to apply the offset to the correct subclass.
These functions look very similar, but only differ in which class is inside the offsetof statement.
The CompositeDataType for the middle class, b, would look like:
Class B has its normal member b, but it also inherits a from its parent class A. In order to pull in the base class member, we call SpecifiedCompositeType<A>::applyMembersToDerived<B>(), and insert these members into our member map. Easy!
Class B also defines its own applyMembersToDerived<Derived> in case anything inherits from B. In this method, the template parameter is also used to call A's applyMembersToDerived function, with the Derived template parameter passed along.
The child class C inherits from B. The defintion for C would look like:
Even though nothing inherits from C, the applyMembersToDerived function is always generated. C does not need to know or care about A, since B takes care of all of that and passes it along to C.
STLs
Currently, STL sequence types (vector, list, deque) are fully supported. All STLs must be explicitly registered with the DataTypeInator (maybe this should change? can we treat them the same as array and pointers?).
All STL field declarations that are found at ICG time are explicitly registered in generated code that looks like
The key method that makes this work is SpecifiedSequenceType<T>::getElementAdddresses(). This is what is used in all of the algorithms to traverse into an STL value. Since some STLs can reallocate themselves, these addresses must NEVER be saved, and getElementAddresses must be called every time we want to traverse into it (pointers work the same way).
Some work will need to be done to figure out how to interact with STLs at runtime through the variable server and input processor.
TypeDefs
Typedef are scraped by ICG and tracked by the DataTypeInator. A user can use their typedef'd names in memory manager declarations.
Namespaces and nested classes
These are supported. ICG tracks what scope each class is declared in, and builds the fully qualified names appropriately. DataTypes must always use fully qualified names.
Currently, there's a nested TypeDictionary structure going on to support namespaces. It recently occurred to me that we probably don't need this at all, just let the name in the TypeDictionary be the fully qualified class name. Fix that eventually.
Class Templates
Class templates are supported. DataTypes has no awareness of class templates, they are just treated as classes with funky names. Class template specializations are represented in the AST as branches under the class template declaration, so it's easy to scrape them in ICG. The fully substituted class template specialization is no different from a normal class, so the code generation is done in exactly the same way.
DataTypes utility classes
The DataTypes have a lot of utilities for parsing and name manipulation that are really helpful for traversal. In particular, a type name MUST be parsed and then reformed before it goes into internal structures in the DataTypeInator to avoid issues with spacing.
Testing
There are 2 test suites for this project - DataType unit tests (under DataTypes/test) and integration tests (under test). All of these use googletest.
The DataType unit tests are pretty straightforward, just make sure they get added to the CMakeLists.txt in that folder.
The ICG integration tests run the whole system. They start with a "user provided" header file(s) containing type definitions, and include a test_main.cpp file that runs test via gtest. Most of these tests use checkpoint/reload as a test.
The ICG tests will run icg <headerfile>, then compile the test_main.cpp file, and the test executable is named after the directory that the test is in. The add_icg_integration_test macro in the test/CMakeLists.txt class does all of this. Follow the pattern in this CMakeLists to add new tests.
I typically add the build/bin directory of this project to my path so that I can easily run icg or individual tests.
Roadmap
Various thoughts on where to go from here are scattered throughout the issues list, but I'll do my best to gather some up here.
Trick Comment parsing
The biggest piece of Trick's capability that is missing here is the comment parsing for units and IO permissions. Comments are included in the AST if generated with the -fparse-all-comments flag. This will take some work, and might require some big refactorings to get the info to the right place. Need to figure out the right way to fit units and IO specification into the DataTypes structure.
REF2 analog
Currently, this project has no analog for the REF2 struct in Trick. A REF2 struct is a reference to a sim variable, so basically you can use the memory manager once to get a reference and then interact with the variable through the reference. Things like the Variable server, data recording, and other parts of Trick that need continuous access to a variable use this. This also handles unit setting and conversion. please for the love of all that is good design this well.
Inheritance edge cases
The inheritance design needs rigorous testing. See details here
Static Variables
I'm not sure what the extent of support for static variable in Trick currently is, but there's no reason not to support them here. I think static variables need to be registered with the memory manager by themselves. This might present a bit of a challenge to figure out the best way to name stuff, but I think it'll be fine. Statics are not implemented in ICG yet, but I don't forsee any blockers here. Github issue here
Bitfields
Bitfields need to be supported, but they kind of break a lot of design assumptions for C++ so they'll be a little messy. Will likely need a BitfieldDataType and SpecifiedBitfieldDataType<T> structure, and will need to be added to the visitors. Github issue here.
Enums
Enums are implemented in DataTypes, but not ICG. Shouldn't be hard, just have to do it. Github issue here
Private Members
Right now ICG does not do any special processing for private/public/protected members, but it will eventually need to do this, or it will generate code that fails to compile due to accessing a private member in the offsetof statement. ICG needs to be smart enough to skip private members.
I think that we can implement a pretty nice friend macro in order to allow ICG to process private members that looks something like:
So if we wanted to process the private members of class Foo, we can add
Inside class Foo.